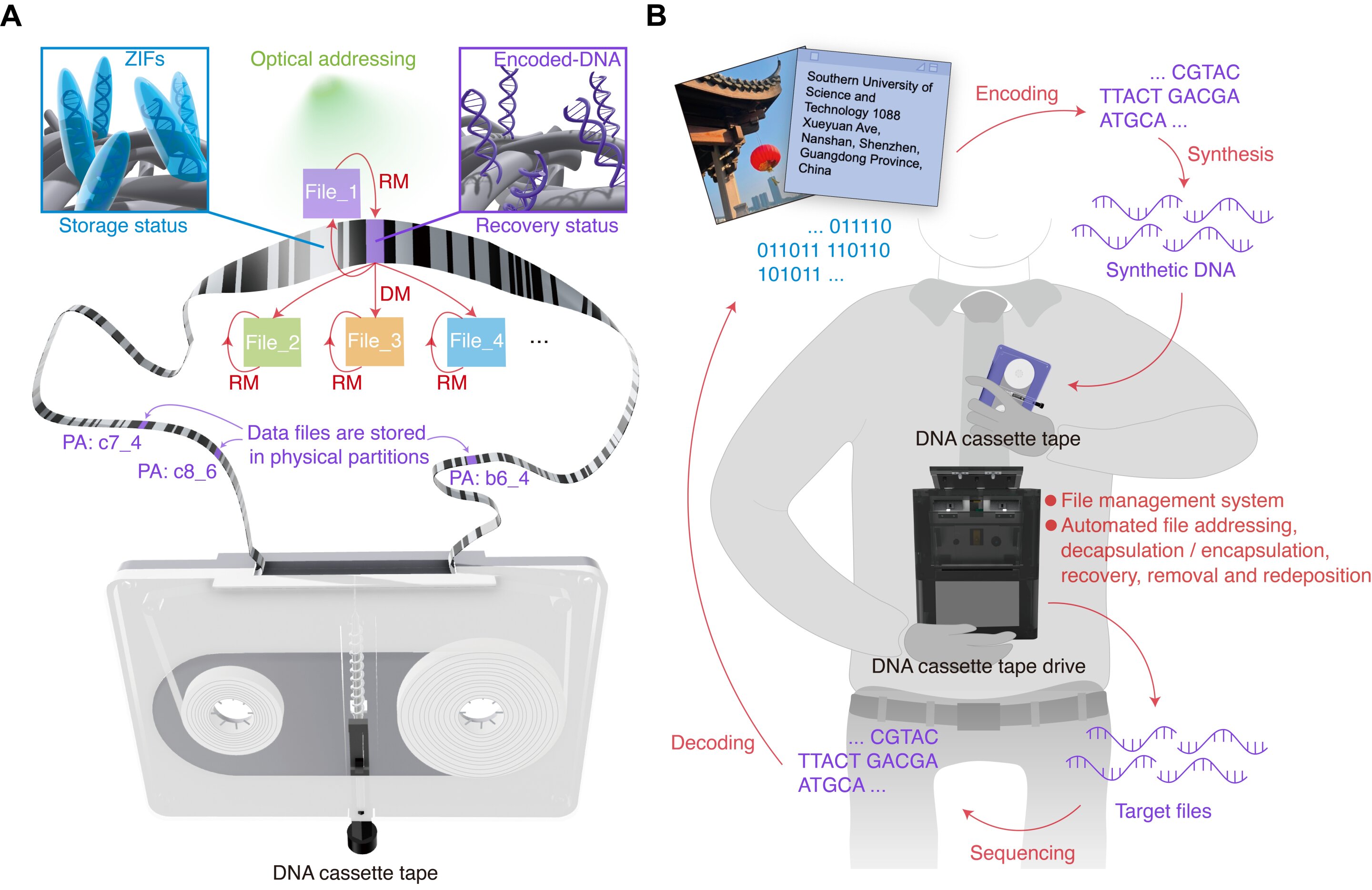
Our increasingly digitized world has a data storage problem. Hard drives and other storage media are reaching their limits, and we are creating data faster than we can store it. Fortunately, we don't have to look too far for a solution, because nature already has a powerful storage medium with DNA (deoxyribonucleic acid). It is this genetic material that Xingyu Jiang at the Southern University of Science and Technology in China and colleagues are using to create DNA storage cassettes.


That’s amazing.
And it doesn’t even need to stop there. Sure, DNA is a convenient starting point - we have enzymes to read and write it, plus it’s a well-studied macromolecule. But that info doesn’t need to be encoded the exact same way biological beings do (a string of phosphate and sugar with pyrimidine and purine-based molecules attached to it). We could do something weird, like
That’s just an example using silicone, mind you. I think you guys get the idea - to use the biological molecules as inspiration, but not force ourselves to do things exactly like nature does.
I know, easier said than done, but think on the benefits of this approach:
The R2S=O case is closer to a trigonal planar geometry, the other silicon is tetrahedral. The silicon-silicon distances for different pairs of adjacent molecule types will be different. In a very very rough forcefield optimization I see about 3% difference. I don’t think this one will work out structurally because the chains will become unable to pair after a short length as the chain will not have the flexibility to create the O–H bond without adding too much strain.
But, that’s just one thing. You then need to consider how to actually selectively place/remove the hydrogen atoms, how to avoid the molecule from chemically reacting, and how to read out the data.
So, yes, eventually it would be nice to have a fully orthogonal system. There are already several synthetic DNA base pairs that can be used instead of the naturally present bases. But these would still be susceptible to DNAses or RNAses.
The way I see it is that the chemistry of living things is currently centuries ahead of human tech. A large portion of the techniques used in biochemistry rely on using living things to produce the components, and then we purify those components and use them. It makes a lot of sense to make use of that toolkit because the amount of challenges that need to be solved to create this system from scratch is massive.
Your proposal of your silicon chain reminds of the Ferroelectric RAM, where the state is encoded by the polarity of a cell that is changed by moving a zirconium or titanium cation:
This does work, but it works because the crystal is contained within a semiconductor scaffold, and this is something that we do have a good handle on.
Fair point - I completely forgot to take the 3D geometry into account. I guess this could be solved by either making both sp³ (sub the Si-O with Si-Cl) or both sp² (sub the H-O-Si with H-N=Si)? But then writing data becomes more complicated than just adding or removing hydrogens that, as you said, isn’t as simple as it looks like.
Like the dNaM / dTPT3 pair, right? That’s perhaps more viable, at least to increase information density.
I think that the solution that life came up with - making a flexible double helix-forming backbone from which base pairs hang is actually a pretty good way of going about it. Similar as with proteins - a standard flexible backbone with different groups hanging off the chain and influencing how it folds. In your proposition you have the silicon backbone and a single atom as the ‘side chain’, so there is no separation between the backbone and the pairing elements to add this flexibility.
There are also some other details to consider. For example, the amount of data you can store in a given chain length changes depending on how many different types of chemistry you have. In your example, you are using only one type of ‘base’ because the only options are ‘hydrogen bond donor’ or ‘hydrogen bond acceptor’. If you have a chain length of 3, you get only 3 bits, which can store one of 2^3 = 8 values from 0 to 7 (000 to 111). With DNA, you have 4 different base pairs, so a chain length of three can encode 4^3 = 64 values.
That means that, to get a good information density, you would also want to increase the number of possibilities. The challenge here is that you need to tune the set of possibilities so that the thermodynamics are balanced. You don’t want some pairs to stick very strongly while others stick only loosely, and you also don’t want certain bases to be able to pair with each other. See: https://en.wikipedia.org/wiki/Nucleic_acid_thermodynamics
You can perhaps dispense with some of the thermodynamic tuning if you don’t need to be able to easily replicate the data through a process similar to DNA replication, as you don’t actually need to ‘pair’ at all - you have a single string of data. But in that case you lose a very powerful method as you are forced to re-synthesize every data chain from scratch - I think that with such a system you lose too many benefits.
If you go through the steps of creating a system of molecular data storage from scratch, I think it is easy to converge towards something similar to DNA. A lot of ‘origin of life’ research is actually about this - thinking about these systems and how to engineer them from scratch, and… DNA is pretty good at this. When you consider that early chemical evolution was an optimization algorithm to solve this problem, it makes sense that DNA is a good choice.
I do think it is good and fun to explore this. We do have at least some advantages over nature - for example, we have managed to purify many compounds that were not abundant in early chemical soups. So, perhaps we can find something.
Yeah, like those. In this recent paper, for example, researchers sequenced a chain of four anthrophogenic base pairs that they refer to as ‘ALIEN bases’: https://www.nature.com/articles/s41467-025-61991-9